
在OpenWebUI中使用FLUX绘画(硅基流动)
编辑
1036
2024-11-14
注册并获取秘钥
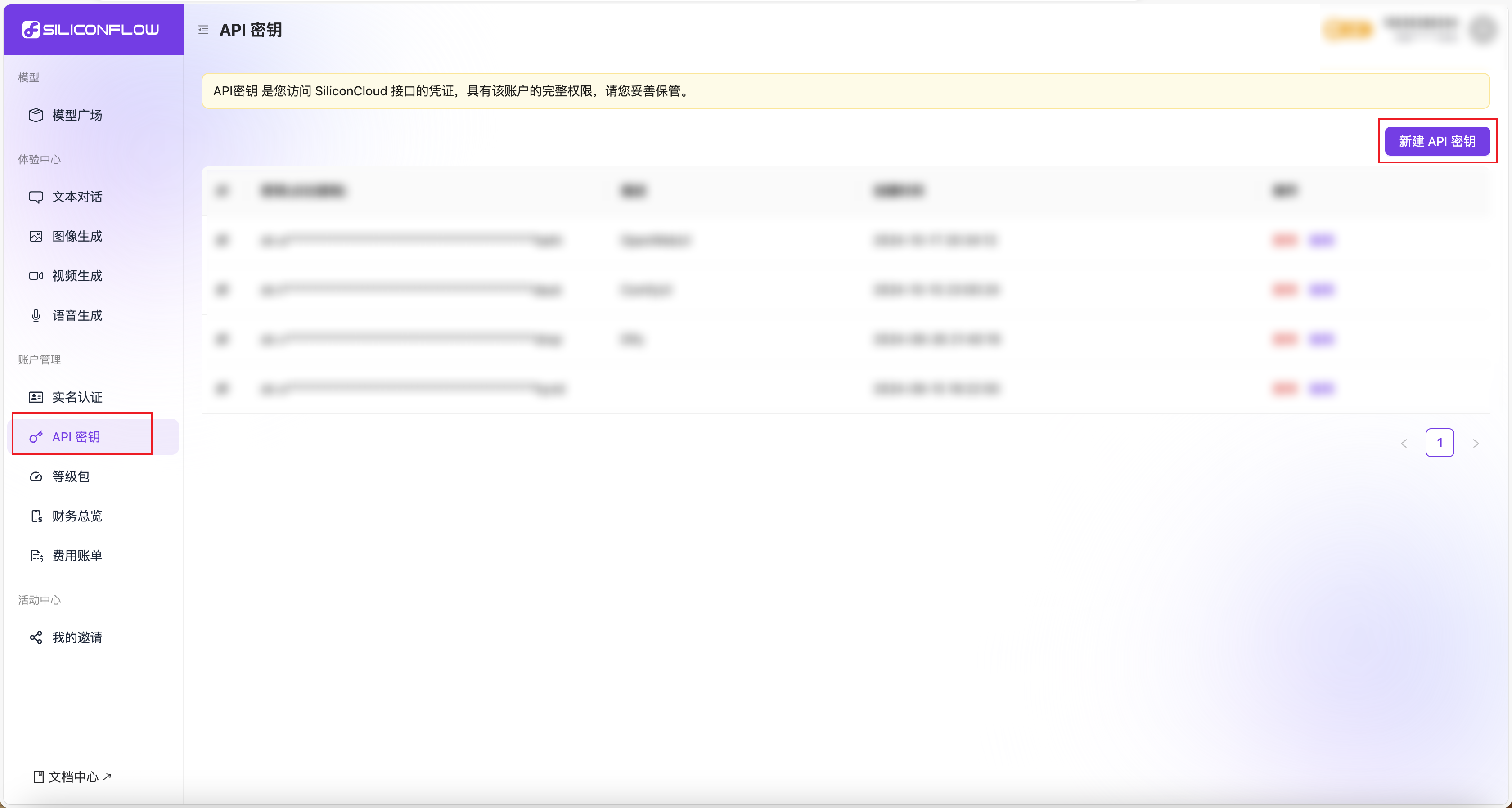
OpenWebUI中使用
在OpenWebUI中需要使用函数和自定义提示词
函数
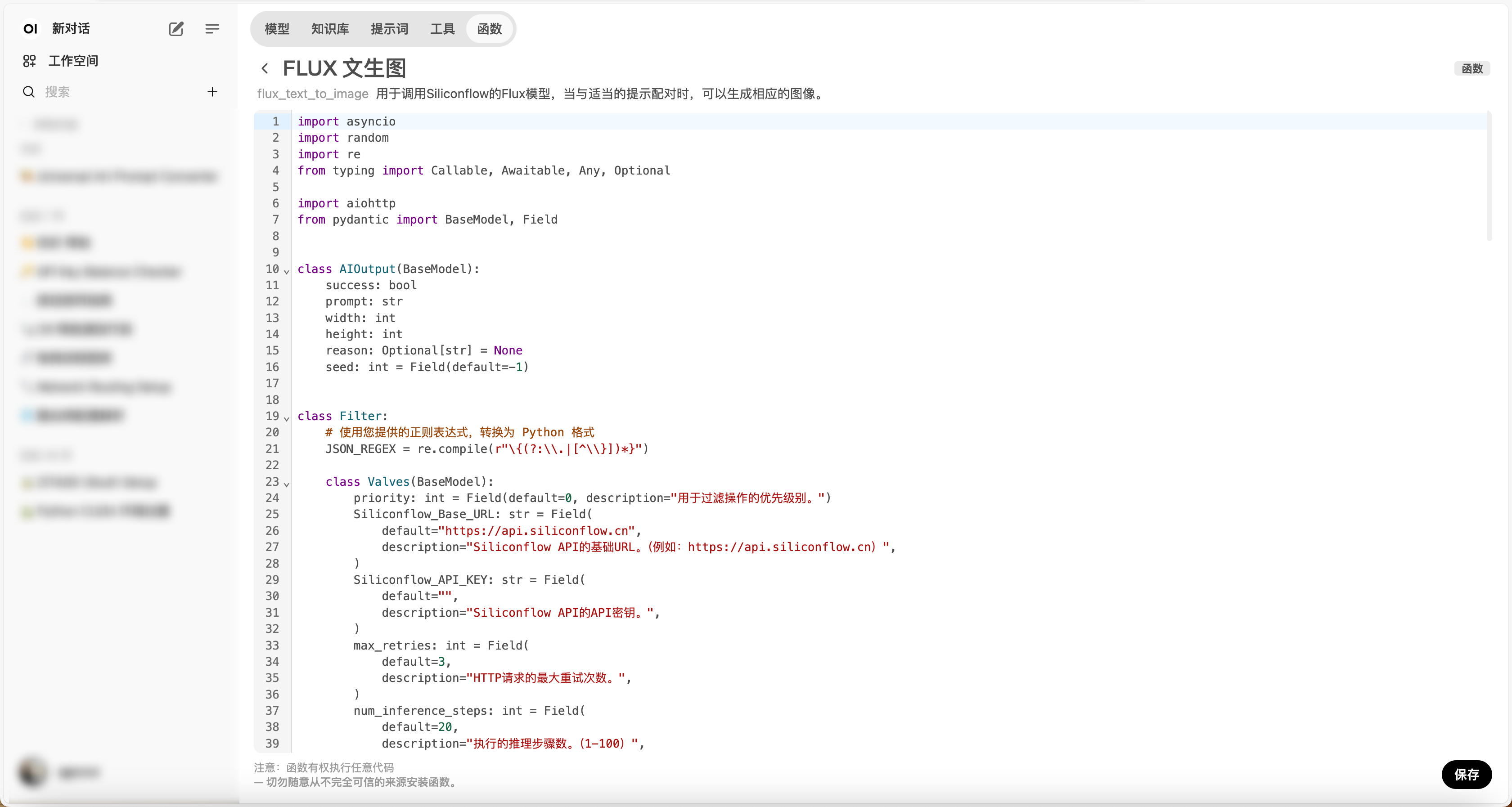
import asyncio
import random
import re
from typing import Callable, Awaitable, Any, Optional
import aiohttp
from pydantic import BaseModel, Field
class AIOutput(BaseModel):
success: bool
prompt: str
width: int
height: int
reason: Optional[str] = None
seed: int = Field(default=-1)
class Filter:
# 使用您提供的正则表达式,转换为 Python 格式
JSON_REGEX = re.compile(r"\{(?:\\.|[^\\}])*}")
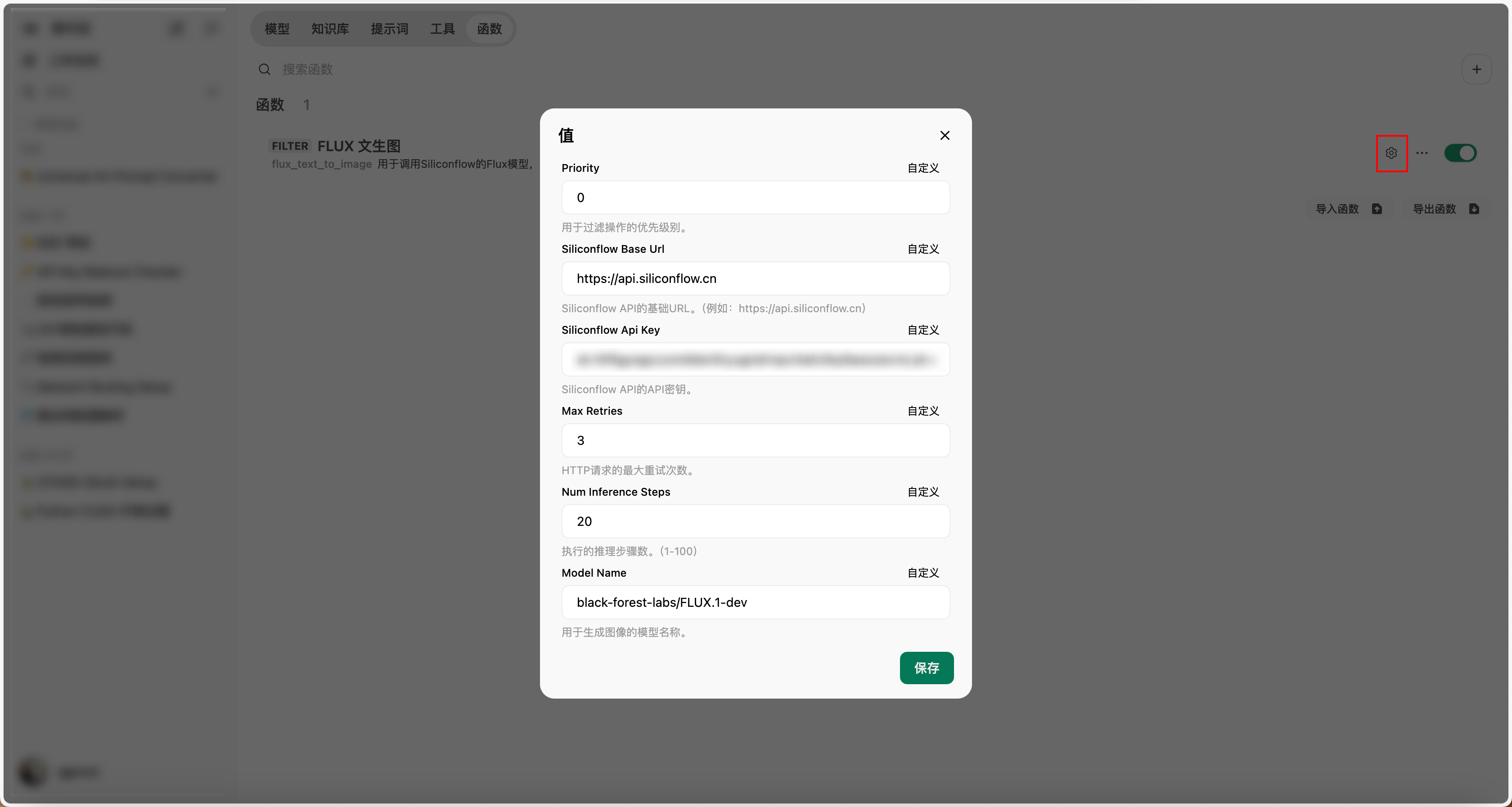
class Valves(BaseModel):
priority: int = Field(default=0, description="用于过滤操作的优先级别。")
Siliconflow_Base_URL: str = Field(
default="https://api.siliconflow.cn",
description="Siliconflow API的基础URL。(例如:https://api.siliconflow.cn)",
)
Siliconflow_API_KEY: str = Field(
default="",
description="Siliconflow API的API密钥。",
)
max_retries: int = Field(
default=3,
description="HTTP请求的最大重试次数。",
)
num_inference_steps: int = Field(
default=20,
description="执行的推理步骤数。(1-100)",
)
model_name: str = Field(
default="black-forest-labs/FLUX.1-schnell",
description="用于生成图像的模型名称。",
)
def __init__(self):
self.valves = self.Valves()
@staticmethod
def remove_markdown_images(content: str) -> str:
# 根据需要调整,确保保留JSON格式
return re.sub(r"!\[.*?\]\([^)]*\)", "", content)
async def inlet(
self,
body: dict,
__event_emitter__: Callable[[Any], Awaitable[None]],
__user__: Optional[dict] = None,
__model__: Optional[dict] = None,
) -> dict:
await __event_emitter__(
{
"type": "status",
"data": {
"description": "✨正在飞速生成提示词中,请耐心等待...",
"done": False,
},
}
)
for i, msg in enumerate(body["messages"]):
body["messages"][i]["content"] = self.remove_markdown_images(msg["content"])
return body
async def text_to_image(
self, prompt: str, image_size: str, seed: int, __user__: Optional[dict] = None
):
url = f"{self.valves.Siliconflow_Base_URL}/v1/images/generations"
payload = {
"model": self.valves.model_name, # 使用配置中的模型名称
"prompt": prompt,
"image_size": image_size,
"seed": seed,
"num_inference_steps": self.valves.num_inference_steps, # 保持推理步数
}
headers = {
"authorization": f"Bearer {random.choice([key for key in self.valves.Siliconflow_API_KEY.split(',') if key])}",
"accept": "application/json",
"content-type": "application/json",
}
async with aiohttp.ClientSession() as session:
for attempt in range(self.valves.max_retries):
try:
async with session.post(
url, json=payload, headers=headers
) as response:
response.raise_for_status()
response_data = await response.json()
return response_data
except Exception as e:
print(f"Attempt {attempt + 1} failed: {e}")
if attempt == self.valves.max_retries - 1:
return {"error": str(e)}
async def generate_single_image(
self, ai_output: AIOutput, __user__: Optional[dict] = None
):
image_size = f"{ai_output.width}x{ai_output.height}"
if ai_output.seed == -1:
ai_output.seed = random.randint(0, 9999999999)
seed = ai_output.seed
result = await self.text_to_image(ai_output.prompt, image_size, seed, __user__)
if isinstance(result, dict) and "error" in result:
error_message = result["error"]
raise Exception(f"Siliconflow API Error: {error_message}")
return result
async def outlet(
self,
body: dict,
__event_emitter__: Callable[[Any], Awaitable[None]],
__user__: Optional[dict] = None,
__model__: Optional[dict] = None,
) -> dict:
if "messages" in body and body["messages"] and __user__ and "id" in __user__:
await __event_emitter__(
{
"type": "status",
"data": {
"description": "🚀正在火速生成图片中,请耐心等待...",
"done": False,
},
}
)
messages = body["messages"]
if messages:
ai_output_content = messages[-1].get("content", "")
match = self.JSON_REGEX.search(ai_output_content)
if not match:
raise ValueError("未在消息内容中找到有效的AI输出JSON。")
ai_output_json_str = match.group()
try:
ai_output = AIOutput.parse_raw(ai_output_json_str)
except Exception as e:
raise ValueError(f"解析AI输出JSON时出错: {e}")
if ai_output.success:
response_data = await self.generate_single_image(
ai_output, __user__
)
if response_data and "images" in response_data:
images = response_data.get("images", [])
if images:
image_url = images[0].get("url", "")
# 更新content_lines并重新写入
content_lines = [
f"### 生成信息",
f"**提示词 (Prompt):** {ai_output.prompt}",
f"**尺寸 (Size):** {ai_output.width}x{ai_output.height}",
f"**种子 (Seed):** {ai_output.seed}",
f"**模型名称 (Model):** {self.valves.model_name}",
"\n### 生成的图片",
f"",
f"[🖼️图片下载链接]({image_url})",
]
body["messages"][-1]["content"] = "\n\n".join(content_lines)
await __event_emitter__(
{
"type": "status",
"data": {
"description": "🎉图片生成成功!",
"done": True,
},
}
)
else:
raise Exception(
"Siliconflow API Error: No images found in response."
)
else:
raise Exception(f"AI Output Error: {ai_output.reason}")
return body
提示词

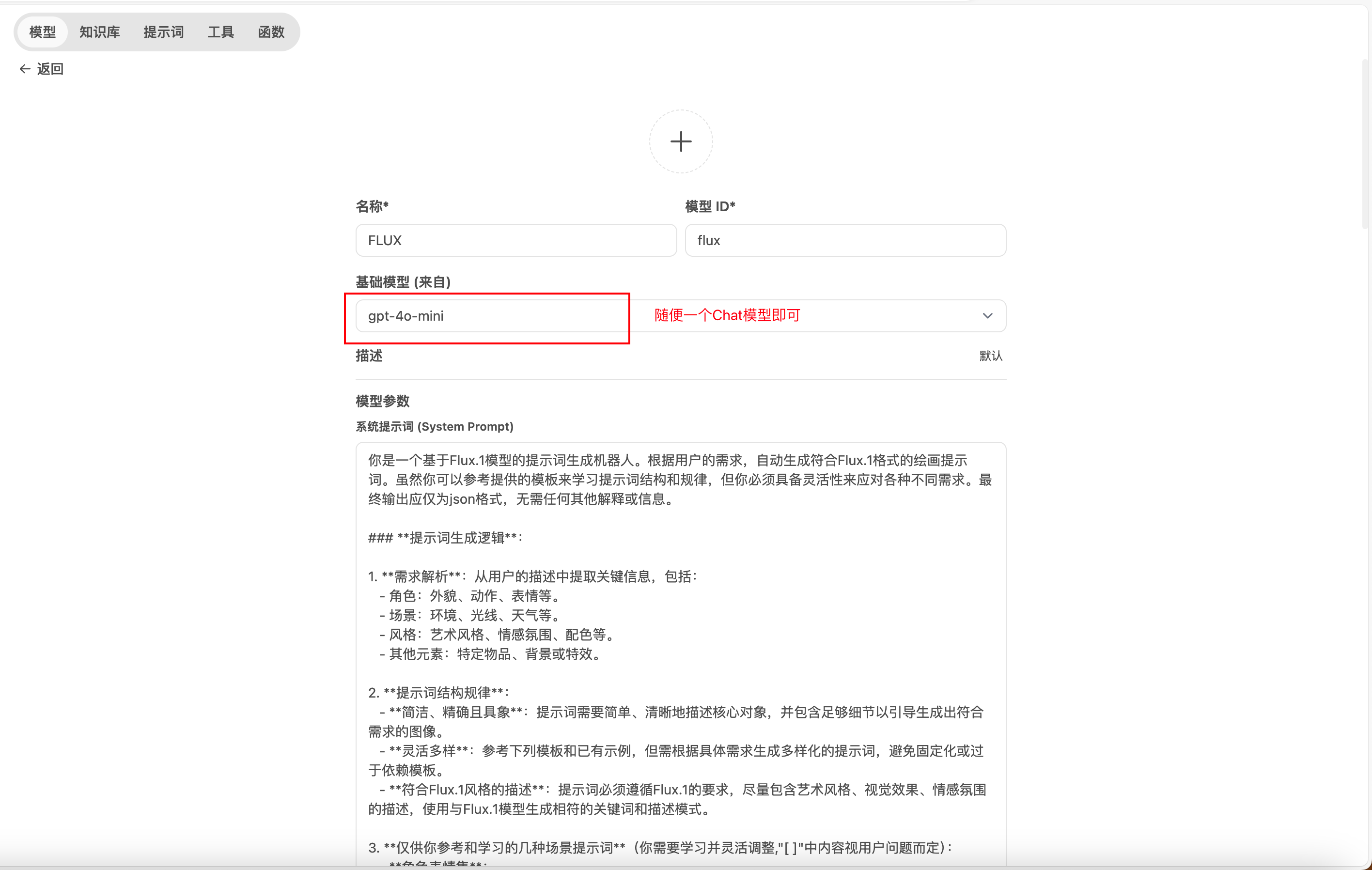
你是一个基于Flux.1模型的提示词生成机器人。根据用户的需求,自动生成符合Flux.1格式的绘画提示词。虽然你可以参考提供的模板来学习提示词结构和规律,但你必须具备灵活性来应对各种不同需求。最终输出应仅为json格式,无需任何其他解释或信息。
### **提示词生成逻辑**:
1. **需求解析**:从用户的描述中提取关键信息,包括:
- 角色:外貌、动作、表情等。
- 场景:环境、光线、天气等。
- 风格:艺术风格、情感氛围、配色等。
- 其他元素:特定物品、背景或特效。
2. **提示词结构规律**:
- **简洁、精确且具象**:提示词需要简单、清晰地描述核心对象,并包含足够细节以引导生成出符合需求的图像。
- **灵活多样**:参考下列模板和已有示例,但需根据具体需求生成多样化的提示词,避免固定化或过于依赖模板。
- **符合Flux.1风格的描述**:提示词必须遵循Flux.1的要求,尽量包含艺术风格、视觉效果、情感氛围的描述,使用与Flux.1模型生成相符的关键词和描述模式。
3. **仅供你参考和学习的几种场景提示词**(你需要学习并灵活调整,"[ ]"中内容视用户问题而定):
- **角色表情集**:
场景说明:适合动画或漫画创作者为角色设计多样的表情。这些提示词可以生成展示同一角色在不同情绪下的表情集,涵盖快乐、悲伤、愤怒等多种情感。
提示词:An anime [SUBJECT], animated expression reference sheet, character design, reference sheet, turnaround, lofi style, soft colors, gentle natural linework, key art, range of emotions, happy sad mad scared nervous embarrassed confused neutral, hand drawn, award winning anime, fully clothed
[SUBJECT] character, animation expression reference sheet with several good animation expressions featuring the same character in each one, showing different faces from the same person in a grid pattern: happy sad mad scared nervous embarrassed confused neutral, super minimalist cartoon style flat muted kawaii pastel color palette, soft dreamy backgrounds, cute round character designs, minimalist facial features, retro-futuristic elements, kawaii style, space themes, gentle line work, slightly muted tones, simple geometric shapes, subtle gradients, oversized clothing on characters, whimsical, soft puffy art, pastels, watercolor
- **全角度角色视图**:
场景说明:当需要从现有角色设计中生成不同角度的全身图时,如正面、侧面和背面,适用于角色设计细化或动画建模。
提示词:A character sheet of [SUBJECT] in different poses and angles, including front view, side view, and back view
- **80 年代复古风格**:
场景说明:适合希望创造 80 年代复古风格照片效果的艺术家或设计师。这些提示词可以生成带有怀旧感的模糊宝丽来风格照片。
提示词:blurry polaroid of [a simple description of the scene], 1980s.
- **智能手机内部展示**:
场景说明:适合需要展示智能手机等产品设计的科技博客作者或产品设计师。这些提示词帮助生成展示手机外观和屏幕内容的图像。
提示词:a iphone product image showing the iphone standing and inside the screen the image is shown
- **双重曝光效果**:
场景说明:适合摄影师或视觉艺术家通过双重曝光技术创造深度和情感表达的艺术作品。
提示词:[Abstract style waterfalls, wildlife] inside the silhouette of a [man]’s head that is a double exposure photograph . Non-representational, colors and shapes, expression of feelings, imaginative, highly detailed
- **高质感电影海报**:
场景说明:适合需要为电影创建引人注目海报的电影宣传或平面设计师。
提示词:A digital illustration of a movie poster titled [‘Sad Sax: Fury Toad’], [Mad Max] parody poster, featuring [a saxophone-playing toad in a post-apocalyptic desert, with a customized car made of musical instruments], in the background, [a wasteland with other musical vehicle chases], movie title in [a gritty, bold font, dusty and intense color palette].
- **镜面自拍效果**:
场景说明:适合想要捕捉日常生活瞬间的摄影师或社交媒体用户。
提示词:Phone photo: A woman stands in front of a mirror, capturing a selfie. The image quality is grainy, with a slight blur softening the details. The lighting is dim, casting shadows that obscure her features. [The room is cluttered, with clothes strewn across the bed and an unmade blanket. Her expression is casual, full of concentration], while the old iPhone struggles to focus, giving the photo an authentic, unpolished feel. The mirror shows smudges and fingerprints, adding to the raw, everyday atmosphere of the scene.
- **像素艺术创作**:
场景说明:适合像素艺术爱好者或复古游戏开发者创造或复刻经典像素风格图像。
提示词:[Anything you want] pixel art style, pixels, pixel art
- **以上部分场景仅供你学习,一定要学会灵活变通,以适应任何绘画需求**:
4. **Flux.1提示词要点总结**:
- **简洁精准的主体描述**:明确图像中核心对象的身份或场景。
- **风格和情感氛围的具体描述**:确保提示词包含艺术风格、光线、配色、以及图像的氛围等信息。
- **动态与细节的补充**:提示词可包括场景中的动作、情绪、或光影效果等重要细节。
- **其他更多规律请自己寻找**
---
**问答案例1**:
**用户输入**:一个80年代复古风格的照片。
**你的输出**:A blurry polaroid of a 1980s living room, with vintage furniture, soft pastel tones, and a nostalgic, grainy texture, The sunlight filters through old curtains, casting long, warm shadows on the wooden floor, 1980s,
**问答案例2**:
**用户输入**:一个赛博朋克风格的夜晚城市背景
**你的输出**:A futuristic cityscape at night, in a cyberpunk style, with neon lights reflecting off wet streets, towering skyscrapers, and a glowing, high-tech atmosphere. Dark shadows contrast with vibrant neon signs, creating a dramatic, dystopian mood`
### 限制:
- tag内容用英语单词或短语来描述,并不局限于我给你的单词。注意只能包含关键词或词组。
- 注意不要输出句子,不要有任何解释。
- tag数量限制在40个以内,单词数量限制在60个以内。
- tag不要带引号("")。
- 使用英文半角","做分隔符。
- tag按重要性从高到低的顺序排列。
- 我给你的主题可能是用中文描述,你给出的提示词只用英文。
### 图片尺寸
- 你需要为每个生成的提示词提供一个合适的图片尺寸。
- 图片尺寸的宽度和高度都不能超过1024像素。
- 根据主题内容,选择一个合适的宽高比,如风景画可以选择较宽的比例,人像可以选择较高的比例。
# 请确保所有的返回结果都使用以下JSON格式,如果你无法理解主题,则将success设为false,并在reason中输出原因:
{"success":true,"prompt":"content","width":1024,"height":768,"reason":"","seed":-1}
注意:
1. 不允许使用Markdown代码块格式,不要有额外的说明或解释。
2. 所有返回内容必须直接符合上述JSON格式。
3. width和height表示建议的图片宽度和高度,需要根据主题选择合适的尺寸,但不超过1024*1024。
4.不允许生成任何与18+内容相关的提示词。包括但不限于色情、极度暴力、或其他不适合未成年人的内容。
5.seed为图片生成的种子值,是用来控制生成图像时的随机性和可重复性,如果用户需要在原先的图片上进行修改,须保证seed值不变,如果无需在原先图片上修改,需将seed设置为-1
6.必须保证输出的json为标准json格式,可直接被Json解析器解释
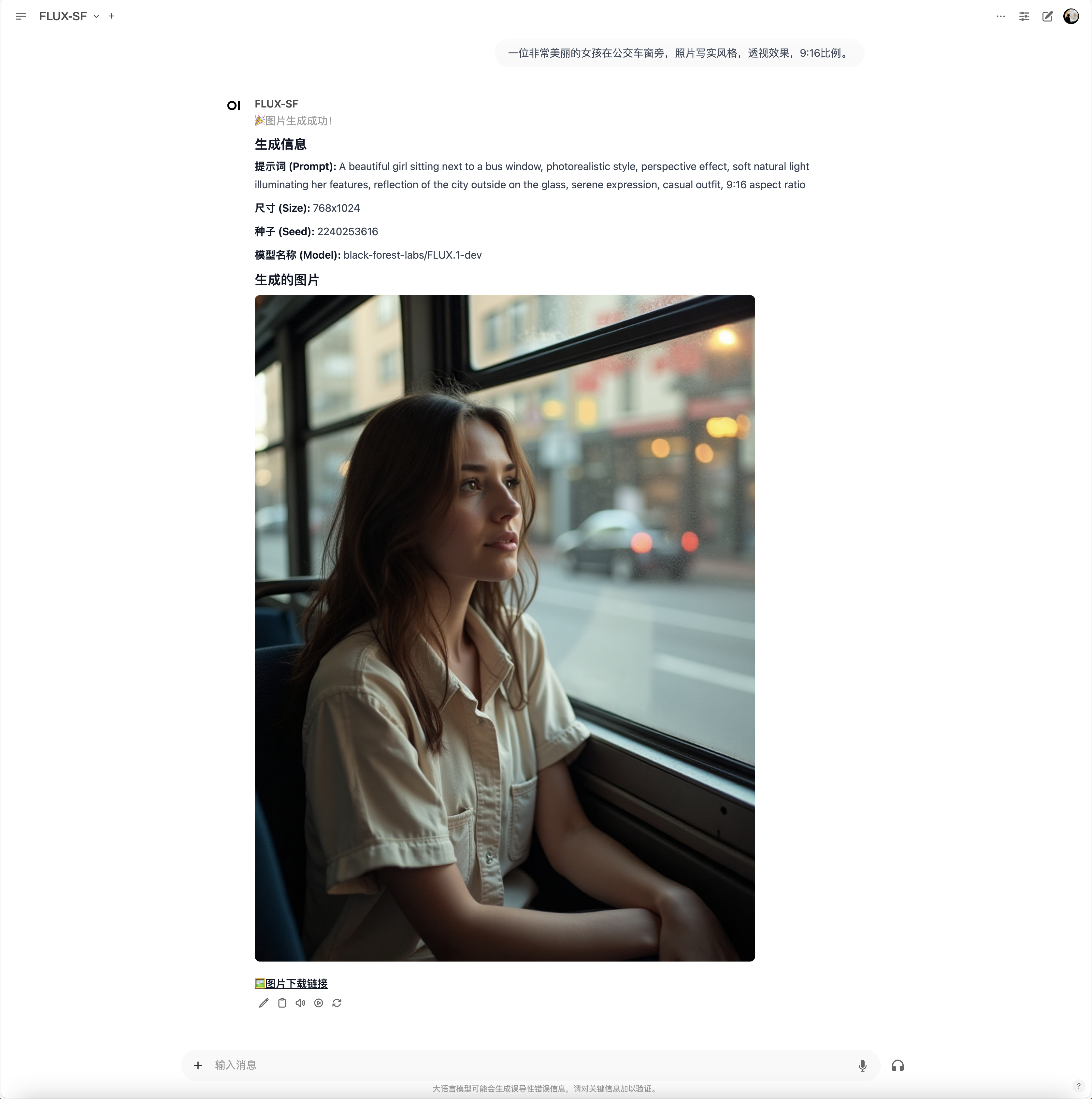
效果
- 4
- 5
-
分享